C 語言浮點數基礎了解
簡介
小數的歷史在數學很早就出現,而電腦第使用浮點數在 1938 年就有了,德國工程師 Konrad Zuse 是先驅。他在 Z1(1938)和 Z3(1941)電腦中使用了 二進位浮點數。
在 1940 年代出現了各種的浮點數實做,像是 1947 年,Bell Labs Model V 使用了十進位的浮點數系統。哈佛馬克一號 (Harvard Mark I) 在 1944 年使用定點數表示浮點數。
1960 年代,各家大公司出來,使用了自己的專屬浮點 數格式,IBM System/360 (1964) 使用 16 進位(Base 16)作為底數,而不是現在通用的 2 進位。這導致精度分佈很不均勻(wobbling precision),但在當時為了速度和範圍做出了妥協。DEC VAX,有自己的一套格式。
關鍵在 1970 年末,Intel 聘請了加州大學柏克萊分校的數學家 William Kahan(後來被稱為「浮點數之父」)。他堅持標準必須設計得非常嚴謹,包含如何處理捨入(Rounding)、非數值(NaN)、正負無窮大等邊界情況。
Intel 在 1980 推出 Intel 8087,這是第一款實作了後來成為 IEEE 754 草案標準的晶片。它的成功證明了這個複雜的標準在硬體上是可行的。
1985 年,IEEE 754-1985 正式發布。2008 年,更新為 IEEE 754-2008,加入了 16-bit 半精度(Half-precision,現在 AI 訓練很常用)和十進位浮點數標準。2019 年,IEEE 754-2019 發布,主要進行了微調和澄清。
IEEE 全名是 Institute of Electrical and Electronics Engineers(電機電子工程師學會)。
它是由兩個美國組織在 1963 年合併而來的(AIEE 和 IRE),一個搞電力的(像愛迪生那派),一個搞無線電的(像馬可尼那派)。
浮點數格式
基礎了解格式請參考 IEEE-754 與浮點數運算 文章,我們這邊簡單了解:
- 單精度浮點數:sign bit (1-bit) + exponent bits (8-bit) + fraction bit (27-bits)
- 雙精確度:sign bit (1-bit) + exponent bits (11-bit) + fraction bit (52-bits)
會有不同的例外,請參考文章。而對於單精度浮點數,其數值公式為:
$$Value = (-1)^S \times (1.F) \times 2^{(E - 127)}$$
兩個相鄰浮點數的最小差異(即尾數 $F$ 改變 1 個 bit),取決於當前的指數 $E$。這個差異被稱為 ULP (Unit in the Last Place)。
$$Gap = 2^{(E - 127)} \times 2^{-23} = 2^{(E - 150)}$$
正體浮點數在數線較靠近 0 的地方,浮點數可以表示非常精細的小數;但當數字變大,兩個相鄰浮點數之間的距離(Gap)也會跟著指數成長。
而在接近 0 的地方會有非正規數,IEEE 754 規定,當指數 (Exponent) 全為 0 時,公式改變
$$Value = 0.M \times 2^{-126}$$
因此很小的數字能緩慢過度到 0。
CPU:「那些小到快要看不見的數字(非正規數),不要浪費時間去算了,直接把它當作 0!」 這個功能主要透過設定 CPU 的控制暫存器(Control Register)來開啟,包含兩個機制:FTZ 和 DAZ。
GCC / Clang: 使用 -ffast-math 開啟。
- 3D 遊戲渲染: 光照計算後的亮度如果是 $0.0000000001$,肉眼根本看不見(顯示器顯示全黑),算那麼準沒意義,直接切成 0 效能最好。
- AI / 深度學習: 神經網路的權重(Weight)如果小到非正規數,通常意味著該神經元未被活化,直接歸零對準確度影響極小,但訓練速度會快很多。
- 音訊處理 (Audio DSP): 這是經典案例。當聲音有「殘響(Reverb)」慢慢消失時,音量會指數衰減進入非正規數區域,導致 CPU 負載在靜音前突然飆高。Audio Plugin 通常預設都會開啟 FTZ。
解決誤差的方法
實際上在運算浮點數會遇到各種問題,不管是數字比較、整數溢位、小數太小消失等各種問題,詳習請看 留意浮點數運算的陷阱,我們下面講一下可能能解決的方式。
Eclipse
既然浮點數一定有誤差,那我們就承認它的存在,不要用 == 來比較,而是看它們「夠不夠接近」。只要 A 和 B 的差距小於一個極小值(Epsilon),就當作它們相等。
float.h 就有定義 FTL_EPSILON 讓我們使用
#include <float.h> // 定義了 FLT_EPSILON
#include <math.h>
int are_equal(float a, float b) {
// 錯誤做法: if (a == b) return 1;
// 正確做法:檢查差值是否小於 Epsilon
return fabs(a - b) < FLT_EPSILON;
}對於非常大的數字,FLT_EPSILON 可能太小(因為 Gap 變大了),進階做法是使用「相對誤差(Relative Epsilon)」,即 fabs(a - b) < epsilon * max(abs(a), abs(b)),但對於小的數字又會失效。
真正最精準是使用 ULP 公式,ULP 是「最後一個位元改變所代表的數值變化量」。 換句話說,如果 A 和 B 是浮點數,它們之間隔了多少個「浮點數刻度」,但實做複雜,
在 Google Test (gtest) 或大型遊戲引擎中,通常採用 “Absolute + Relative” 的混合策略。
請參考 浮点,多少老司机的血泪史 文章。
Kahan Summation (補償加法)
當你要把幾百萬個浮點數加總時,誤差會累積得非常可怕(大數吃小數)。1965 年,威廉·卡漢(William Kahan,IEEE 754 之父)發明了一個演算法來解決這個問題。
原理: 用一個額外的變數 c 來記錄「被捨棄掉的微小誤差」,在下一次加法時把它補回來。
float kahan_sum(float* input, int n) {
float sum = 0.0f;
float c = 0.0f; // 用來存誤差 (Running compensation)
for (int i = 0; i < n; i++) {
float y = input[i] - c; // 減去上次的誤差,試圖修正
float t = sum + y; // 暫存加法結果
// 這裡是用數學魔法算出「這次加法損失了多少精度」
// (t - sum) 是實際被加進去的數字,減掉 y 就是損失的部分
c = (t - sum) - y;
sum = t;
}
return sum;
}請參考 Kahan 求和 文章。
Kahan 雖然可以把 float 的有效精度提升到接近 double 的水準,但它並沒有把精度變成無限大。如果數量級差異超過了有效位數的極限(約 2 倍位寬),它依然會失敗。
針對這種情況,後來有改良版的 Neumaier Summation,它多了一些判斷邏輯來處理輸入值比 Sum 還要大的情況,比 Kahan 更穩健,但也更慢。

軟體模擬
FPU Emulation,用「陣列」來存數字。想算 1000 位數的小數?沒問題,就開一個長度 1000 的陣列。
像是函式庫:
- GMP (GNU Multiple Precision Arithmetic Library): C 語言最強大的高精度庫。
- MPFR: 專門做正確捨入的高精度浮點運算。
- Python 的 decimal 模組 / Java 的 BigDecimal。
代價: 超級慢。比硬體運算慢 10 倍到 100 倍以上。通常只有科學研究或加密演算法(Cryptography)會用到。
定點數
把所有數字放大 N 倍,全部用整數 (Integer) 來算。像是 Linux Kernel 就是這樣,或者嵌入式系統。
Linux 實做如下:
- 1.0 在核心裡被表示為 2048 (1 « 11)。
- 0.5 在核心裡被表示為 1024。
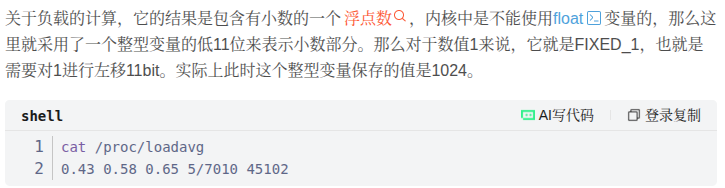
或者請參考 Linux 核心設計: Load average。
或者針對一些定點數算不出來的東西,像是自然對數的次方,就會用查表的方式。

但真的,有時候會有無可避免要在核心使用 Float point,這時候參 Floating-point API 說的,有些驅動程式(Driver)或加解密函式庫(如 RAID校驗、AES-NI 加密)確實需要用到浮點數運算(SIMD 指令)。Linux 允許這種情況,但有嚴格規定:
- 程式碼隔離 (Separate Translation Unit): 包含浮點數運算的函式必須放在一個「獨立的 .c 原始檔」中。
- 關鍵區段 (Critical Sections): 在呼叫這些函式的前後,必須手動建立「浮點數關鍵區段」。這包含了保存(Save)與還原(Restore)原本的暫存器狀態。
為什麼要隔離? 如果把浮點數程式碼跟一般 Kernel 程式碼混在同一個檔案,編譯器可能會「雞婆」地進行優化。例如,編譯器發現浮點暫存器比較寬(128-bit / 256-bit),可能會偷偷用它來加速 memcpy 或變數賦值。如果這發生在關鍵區段之外,就會破壞 Userspace 的資料。
其他
其實還有更多想處理浮點數的方法,像是
- Posit (Unum Type III): 這是 John Gustafson 在 2017 年提出的新格式。
- 硬體直接提供硬體指令,像是 Fused Multiply-Add
- 使用數學,當你要連乘很多個小於 1 的機率(例如 $0.1 \times 0.1 \times \dots$ 乘 100 次),數值會迅速變小,最後發生 Underflow (下溢) 變成 0。所以直接把所有數字取 Log (對數),乘法變成加法
TPU BFloat16
在最新,Google 還是有對 Floating point 有工作,它是由 Google Brain 團隊為了 TPU (Tensor Processing Unit) 專門發明的格式,為什麼可以這樣設計呢?
BF16 的指數跟 FP32 一模一樣 (8 bits),它的數值範圍就跟 FP32 完全一樣,工程師不需要擔心溢位問題,完全不需要 Loss Scaling,程式碼可以直接從 FP32 轉過來跑,無痛遷移。
所以他是一個砍掉尾數、保留指數的 FP32,而這樣唯一的缺點就是精確度變爛,但神經網路不擔心此問題。
神經網路本質上是在處理機率和權重,充滿了雜訊。 Google 實驗發現:AI 模型對「尾數」的精度非常不敏感。 就算你小數點後第 4 位算錯了,神經網路透過多次迭代(Iteration)還是會自我修正回來。因此只要指數(數量級)對了,尾數差一點點沒關係。
Nvidia FP8
在 AI 訓練中,傳統使用 FP16 或 BF16(16 位元)來儲存數據。但為了追求更快的速度,NVIDIA 推出了 FP8(8 位元)。

雖然 FP8 只有 8 位元,但 NVIDIA 宣稱透過特殊的 Tensor Core 累加技術,精度可以維持在接近 16 位元的水準。
DeepSeek 在 2024/12 發布 V3 模型時,揭露了他們如何用極低成本訓練出頂尖模型。但技術報告中埋了一個伏筆:「NVIDIA H800 的 FP8 GEMM(矩陣乘法)累加精度大約只有 14 bits」。
隨後,SageAttention2 團隊發布論文 in 2025/01,透過精密的數學測試驗證了 DeepSeek 的直覺。 他們發現 NVIDIA 的 Tensor Core 在處理 FP8 累加時,並不是採用完整的 FP32 精度累加,而是存在一種 「截斷行為」 (Truncation)。這證實了這不是軟體 Bug,而是硬體設計上的妥協——為了換取極致的吞吐量,NVIDIA 犧牲了部分尾數的精度。
PyTorch 團隊在 2025 年 2 月發布了一篇標題極具嘲諷意味的文章:《有些矩陣乘法引擎並不像我們想像的那麼精確》。